
This past week, Connie and I spent most of our time learning the ins-and-outs of Wax. My primary activity was geared toward how to change the website’s style. Working with Wax brought up some key challenges related to technology choices into focus.
Sometimes when you’re working on a web development project with a small team, progress often takes longer than you think to start, but progresses faster than expected. As much as the ideal of iterative work lives on in project planning, most of our progress has some in fits and starts. Part of the slowness to is learning new domains, as required by sourcing the visual media for our archive. But another aspect, a focus of this post, has been learning technical tool from scratch.
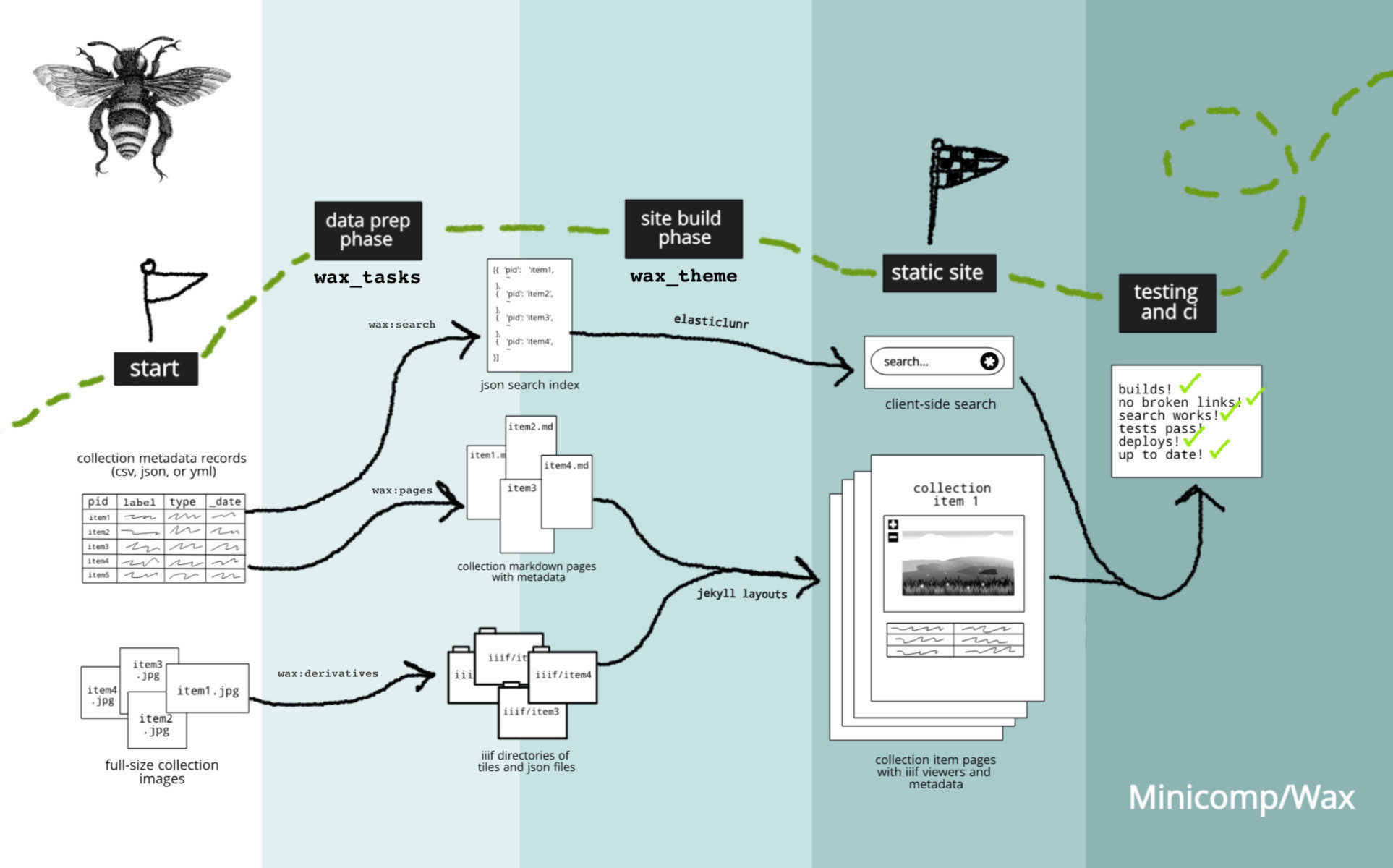
While the Wax documentation owns up to a learning curve being “best suited for folks who are willing to take on some technical responsibility in exchange for a lot of flexibility,” the nature of statically generated site engines is that complexity is kept as minimal as possible. In fact, a Wax workflow image represents a basic explanation of how a Wax site as built. What I didn’t anticipate was the complication of additional framework/tools bundled with this particular library.
One example that we stumbled on several times during the stylistic changes was the inheritabilty of CSS/Sass used via Bootstrap. For two people with limited front end development experience, it’s hard to understand where to change fonts, colors for background, hover-overs links and text. The documentation suggests forking the Wax demo project from their repository then “clobbering” the collection using RAKE. These actions yield a complete, working set of styling and interactivity for the website with Bootstrap, but no straight forward landing spot for the new archivist without frontend design skills to update the design of their new website.
There are three Sass files in two directories that determine the CSS compiled when the site is generated.
Three Sass files in two directories
All three of these files interact and depend on each other in different ways. A couple of times during this week, we struggled to understand exactly how the update a font, or a hover over color. Should we update the font-family? What about the $body-text variable created via Sass? At best, we got a compile time error when we forget to add a semicolon. We were able to make stylistic changes in the end, but if we need to make additional changes, we might not exactly remember what we did, and whether or not all of the steps we took were necessary in the end.
Some other struggles came up beyond changing styles. We still haven’t discovered why about 20% of the images we’ve uploaded don’t render on our website. Debugging this is a challenge given the size of the Wax project.
Another slate of problems we didn’t foresee are related to performance from a developer perspective. From start to finish, generating the collection takes over two hours! If you add or remove images from a collection, it’s required to rebuild the entire collection, triggering a long process working through +500 images. In a similar vein, generating the static website currently takes more than twenty seconds locally, and six and a half minutes to be deployed. I consulted a friend who formerly used Jekyll for their personal development blog, and they claimed it told four hours to build two years worth of posts. My hunch is that this is related to Digital Humanities comfortability in shipping prototypes and smaller projects, and that our collection is a little too large for Jekyll generator, being built in Ruby, a relatively slow interpretative language. These performance issues almost led to us shifting our archive over to Hugo, a static site generator build in Go , which would ameliorate any performance issues, but we decided against it due to time constraints and the introduction to yet another topic to learn about.
As mentioned before, we will likely scale down the types of media available on the archive. Given the performance issues, we wouldn’t want to experiment heavily with embedding videos, and will opt to include those on a resources page with appropriate links. I suspect we’ll be learning more about the ins-and-outs of Bootstrap, CSS, and Sass for the next week to continue to form the website appropriately given our content. We also need to focus on furnishing the appropriate context and text for the archive to give vistors a sense of themes and purpose of the website sooner rather than later. I’m still confident we will meet our shipping date in two weeks, just that it will be a rough draft we’ll need to polish in the remaining two weeks of the class.





{kind=link}